Tabular Data Augmentations
Tabular Data Augmentations
표 데이터 증강
이미지나 가끔은 텍스트/시계열 데이터에서 데이터 증강이 효과적임을 보곤한다. 강아지 이미지가 회전을 하더라도 강아지이고, 신경망은 이를 이해할 수 있다.
하지만 tabular data를 다룰 때는 상황이 약간 달라진다. table을 회전하거나 확대/축소를 할 수는 없으니.
그렇다면 뭘 해야할까?
Simple Noise (Jitter)
간단히 말해서, columns 그 자체에 노이즈를 추가 할 수 있다.
이 방식에서 간단한 개선 사항을 생각한다면, 노이즈를 추가하려 할 때 columns의 표준편차(std)를 고려하는 것이다.
Swap Noise
이 방법은 같은 feature column에 있는 값을 다른 값과 swapping 하는 것이다. (feature간에선 섞지 말고)
이렇게 하면 결과물이 각 feature에 맞는 값을 여전히 포함하는 feature column이 된다.
def apply_noise(df, p=.75):
should_not_swap = np.random.binomial(1, p, df.shape)
corrupted_df = df.where(should_not_swap == 1, np.random.permutation(df))
return corrupted_df
swap noise의 종류
배치 크기와 feature space 크기를 5라고 하고, noise가 발생할 확률을 20%라 하자.
columnwise swap noise
전체 columns중 배치 크기의 20%에서만 노이즈를 발생시키는 방법

Randomized swap noise
무작위로 20%의 노이즈 값을 추가하는 방법
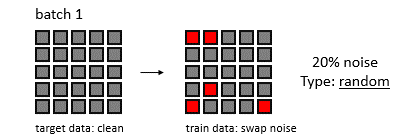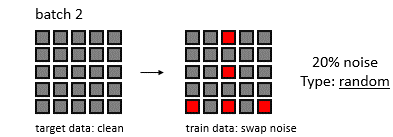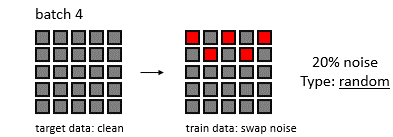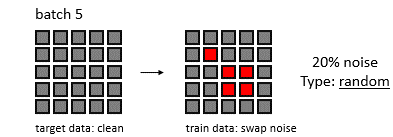
Rowwise swap noise
각 행별로 20%의 노이즈를 추가하는 방법

MixUp, CutMix
Computer Vision에서 자주쓰는 방법으로 tabular 데이터에선 행에 대한 선형 조합으로 구현할 수 있다.


CTGan
이 논문에서 tabular data를 위한 GAN 구조를 제안하였다. 과거 kaggle에서 사용된 적이 있따.

참고
https://www.kaggle.com/competitions/amex-default-prediction/discussion/332930