-
Probability calibration인공지능(Artificial Intelligence)/기계학습(Machine Learning) 2022. 7. 11. 11:09
Probability calibration
확률 보정
Building Machine Learning Porwed Applications의 5.2.4에 보정 곡선이라는 내용이 나온다. 모델 평가에 대한 내용 중 일부로 오차 행렬 (Confusion Matrix), ROC 곡선 (ROC Curve) 다음에 등장하는 내용이다. 책에서는 다음과 같이 보정 곡선에 대해 설명한다.
"이진 분류 작업에 유용한 또 다른 그래프이며 모델 출력 확률을 신뢰할 수 있는지 가늠하는데 도움이 된다. 분류기의 신뢰도에 대한 함수로 진짜 양성 샘플의 비율을 나타낸다."
기계학습을 공부하며 처음 알게 된 평가방법으로 조금 더 자세히 알아보기로 하였다. 참고 내용은 가장 하단에 링크로 정리되어있다.
우선적으로 확률 보정에 대해 이해해야 한다.
우리가 분류 작업을 수행할 때, 예측된 클래스 뿐만 아니라 그에 연관된 확률도 얻는데 이는 예측에 대한 일종의 확신을 일컸는다. 확률 보정인 여기서 주어진 모델의 확률을 보정하거나 확률 예측에 대한 support를 추가한다. (SVM 같은 경우)
보정 곡선
보정 곡선 (Calibration Curves, reliability diagrams)은 이진 분류기의 확률 예측이 얼마나 잘 보정되었는지 비교해주는데, binned 예측에 대해 예측 확률에 대한 양성 레이블의 실제 빈도를 그려준다. x축은 각 bin에 대한 평균 예측 확률을 나타내며, y축은 각 bin에서 클래스가 양상 클래스인 비율을 나타낸다.
밑에 그림에서 볼 수 있다. 여기서 점선으로 그려진 대각선은 완벽한 모델을 보정 곡선에 대한 그림을 나타낸다.
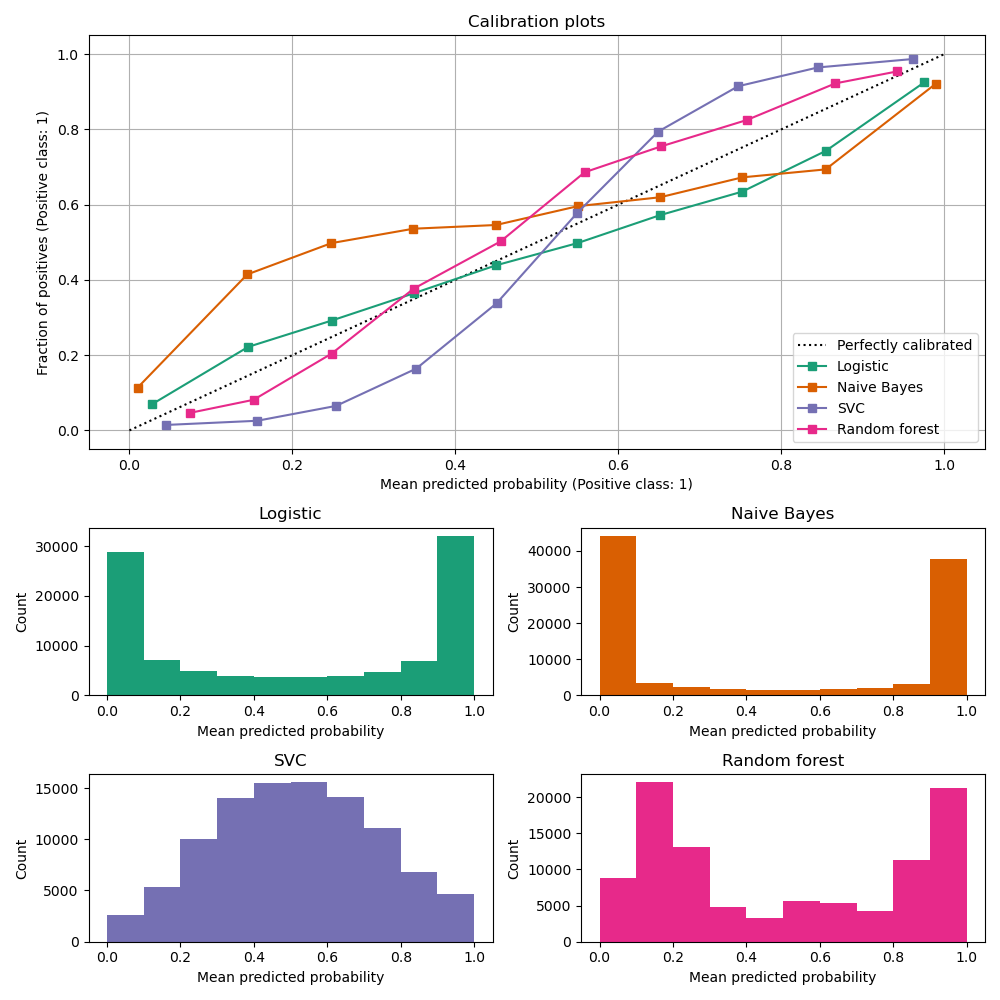
Logistic Regression은 Log Loss를 사용하기에 기본적으로 잘 보정된 예측값을 반환한다.반대로 다른 방법들은 편중된 확률을 준다. (방법마다 편중이 다르다.)
Naive Bayes는 예측 확률을 0이나 1로 나타내는 경향이 있다. 왜냐하면 주어진 클래스에 대해 주어진 특징이 조건부 독립이라는 가정 때문에 그렇다.
Random Forest는 반대의 경향을 보인다. 0.2와 0.9에서 가장 많은 확률 카운트를 보인다. 이에 대한 설명은 Niculescu-Mizil과 Caruana의 말을 빌릴 수 있는데 "기본 모델로부터 예측을 평균내는 bagging과 Random Forest와 같은 방법(즉 앙상블)은 0과 1에 가까운 예측을 만들어내는데 어려움을 갖는데 왜냐하면 기본 모델에 깔려있는 variance이 예측을 편향(bias)해 예측값을 0과 1에서 멀어지게 하기 때문이다. 예측 확률이 0과 1의 범위로 한정되었기에, variance로 발생되는 오류는 0과 1의 근처에서 발생하는 경향이 있다. bagging의 경우 한 케이스에 대해 모든 bagged tree가 예측 확률을 0이라고 예측해야만 최종 예측 확률이 0이라고 할 수 있다. 만약 bagging이 평균을 내는 tree에 noise를 더한다면, 어떤 tree의 경우 그 케이스에 대해 0보다 큰 예측값을 만들 것이고 bagging은 0보다 큰 예측확률을 만들어 낼 것이다. Random Forest에서 이런 경우를 많이 관측할 수 있는데, Random Forest의 base-level tree는 feature subsetting 때문에 상대적으로 높은 variance를 갖기 때문이다"
결과적으로, 보정 곡선은 특징적인(Characteristic) S자 형태 (Sigmoid)를 그리며, 이는 분류기가 "직관"을 더 신뢰할 수 있고 일반적으로 0 또는 1에 가까운 확률을 반환할 수 있음을 나타낸다.
Linear Support Vector Classification은 Random Forest보다 더 심한 S자 형태를 보여주는데, 이는 maximum-margin method로 인해 나타나는 현상이다.; Maximum-margin method는 decision boundary에 가까이에 있는 분류하기 힘든 샘플에 집중하기 때문이다.
분류기 보정하기
분류기를 보정하는 것은
참고
[1] https://en.wikipedia.org/wiki/Calibration_curve
[2] https://scikit-learn.org/stable/modules/calibration.html#calibration
'인공지능(Artificial Intelligence) > 기계학습(Machine Learning)' 카테고리의 다른 글
KAGGLE ENSEMBLING GUIDE (0) 2022.06.27 Tabular Data Augmentations (0) 2022.06.27 Activation Function (0) 2022.04.29